लेखक:
Charles Brown
निर्मितीची तारीख:
9 फेब्रुवारी 2021
अद्यतन तारीख:
1 जुलै 2024

सामग्री
वर्गांची बेरीज किंवा एसएसई ही एक प्राथमिक सांख्यिकीय गणना आहे जी भिन्न डेटा मूल्यांकनाकडे नेते. आपल्याकडे डेटा व्हॅल्यूजचा सेट असतो तेव्हा या व्हॅल्यूज किती जवळच्या संबंधित आहेत हे निर्धारित करण्यास सक्षम असणे उपयुक्त ठरेल. आपल्याला एका डेटामध्ये आपला डेटा आयोजित करावा लागेल आणि नंतर ब simple्यापैकी सोपी गणना करावी लागेल. एकदा आपल्याला डेटा सेटसाठी एसएसई सापडला की आपण नंतर भिन्नता आणि मानक विचलन शोधू शकता.
पाऊल टाकण्यासाठी
पद्धत 3 पैकी 1: हाताने एसएसईची गणना करा
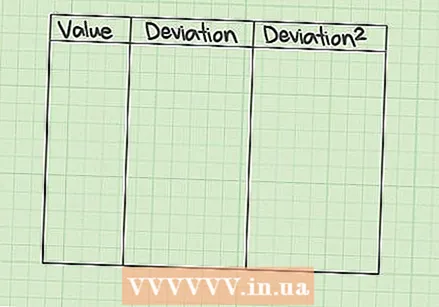 तीन-स्तंभ सारणी तयार करा. एसएसईची गणना करण्याचा सर्वात स्पष्ट मार्ग म्हणजे तीन स्तंभ सारणीसह प्रारंभ करणे. तीन स्तंभ लेबल करा
तीन-स्तंभ सारणी तयार करा. एसएसईची गणना करण्याचा सर्वात स्पष्ट मार्ग म्हणजे तीन स्तंभ सारणीसह प्रारंभ करणे. तीन स्तंभ लेबल करा  तपशील भरा. पहिल्या स्तंभात आपल्या मोजमापांची मूल्ये आहेत. कॉलम भरा
तपशील भरा. पहिल्या स्तंभात आपल्या मोजमापांची मूल्ये आहेत. कॉलम भरा  मधे मोजा. आपण प्रत्येक मापनासाठी त्रुटीची गणना करण्यापूर्वी, आपण संपूर्ण डेटा सेटच्या मध्यमाची गणना करणे आवश्यक आहे.
मधे मोजा. आपण प्रत्येक मापनासाठी त्रुटीची गणना करण्यापूर्वी, आपण संपूर्ण डेटा सेटच्या मध्यमाची गणना करणे आवश्यक आहे. - डेटा सेटचा अर्थ म्हणजे सेटमधील मूल्यांच्या संख्येद्वारे विभाजित केलेल्या मूल्यांची बेरीज. हे व्हेरिएबलसह प्रतिकात्मकपणे दर्शविले जाऊ शकते
 वैयक्तिक त्रुटींच्या मूल्यांची गणना करा. आपल्या टेबलच्या दुसर्या स्तंभात, आपण प्रत्येक डेटा मूल्यासाठी त्रुटी मूल्य प्रविष्ट करणे आवश्यक आहे. त्रुटी म्हणजे मोजमाप आणि सरासरीमधील फरक.
वैयक्तिक त्रुटींच्या मूल्यांची गणना करा. आपल्या टेबलच्या दुसर्या स्तंभात, आपण प्रत्येक डेटा मूल्यासाठी त्रुटी मूल्य प्रविष्ट करणे आवश्यक आहे. त्रुटी म्हणजे मोजमाप आणि सरासरीमधील फरक. - दिलेल्या डेटा सेटसाठी, प्रत्येक मोजल्या गेलेल्या मूल्यापासून 98.87 पर्यंतचे वजा करा आणि परिणामासह दुसर्या स्तंभ भरा. या दहा गणना खालीलप्रमाणे आहेत:
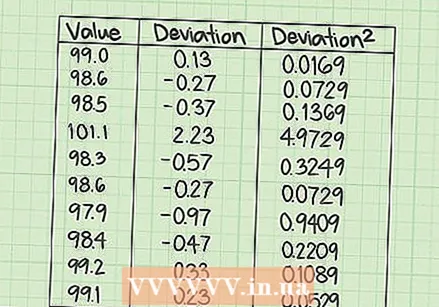 एसएसईची गणना करा. टेबलच्या तिसर्या स्तंभात, मध्यम स्तंभातील परिणामी मूल्यांच्या प्रत्येकाचा वर्ग शोधा. हे प्रत्येक मोजलेल्या डेटा मूल्यासाठी क्षमतेपासून विचलनाचे वर्ग दर्शविते.
एसएसईची गणना करा. टेबलच्या तिसर्या स्तंभात, मध्यम स्तंभातील परिणामी मूल्यांच्या प्रत्येकाचा वर्ग शोधा. हे प्रत्येक मोजलेल्या डेटा मूल्यासाठी क्षमतेपासून विचलनाचे वर्ग दर्शविते. - मध्यम स्तंभातील प्रत्येक मूल्यासाठी, चौरस काढण्यासाठी कॅल्क्युलेटर वापरा. तिसर्या स्तंभात खालीलप्रमाणे परिणाम नोंदवाः
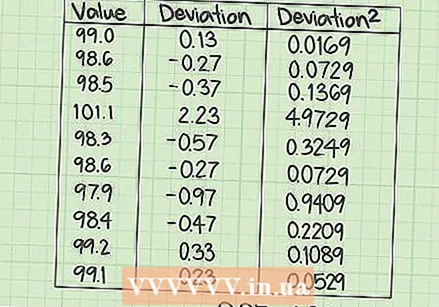 त्रुटींचे वर्ग जोडा. शेवटची पायरी म्हणजे तिसर्या स्तंभातील मूल्यांची बेरीज शोधणे. इच्छित परिणाम म्हणजे एसएसई किंवा त्रुटींच्या वर्गांची बेरीज.
त्रुटींचे वर्ग जोडा. शेवटची पायरी म्हणजे तिसर्या स्तंभातील मूल्यांची बेरीज शोधणे. इच्छित परिणाम म्हणजे एसएसई किंवा त्रुटींच्या वर्गांची बेरीज. - या डेटा सेटसाठी, एसएसईची गणना तिसर्या स्तंभात दहा मूल्ये जोडून केली जाते:
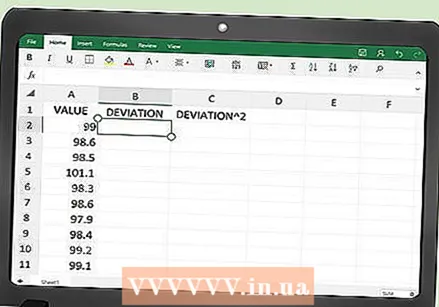
 स्प्रेडशीटच्या स्तंभांवर लेबल लावा. आपण वर सारख्या तीन शीर्षकासह एक्सेलमध्ये तीन स्तंभांसह एक टेबल तयार करा.
स्प्रेडशीटच्या स्तंभांवर लेबल लावा. आपण वर सारख्या तीन शीर्षकासह एक्सेलमध्ये तीन स्तंभांसह एक टेबल तयार करा. - सेल A1 मध्ये, शीर्षक म्हणून "मूल्य" टाइप करा.
- बॉक्स बी 1 मध्ये, शीर्षक म्हणून "विचलन" टाइप करा.
- बॉक्स सी 1 मध्ये, शीर्षक म्हणून "डिव्हिएशन स्क्वेअर" टाइप करा.
 आपले तपशील प्रविष्ट करा. पहिल्या स्तंभात आपल्याला आपल्या मोजमापाचे मूल्य प्रविष्ट करावे लागेल. जर सेट छोटा असेल तर आपण त्यास हाताने टाइप करू शकता. आपल्याकडे मोठा डेटा सेट असल्यास आपल्याला कॉलममध्ये डेटा कॉपी आणि पेस्ट करावा लागेल.
आपले तपशील प्रविष्ट करा. पहिल्या स्तंभात आपल्याला आपल्या मोजमापाचे मूल्य प्रविष्ट करावे लागेल. जर सेट छोटा असेल तर आपण त्यास हाताने टाइप करू शकता. आपल्याकडे मोठा डेटा सेट असल्यास आपल्याला कॉलममध्ये डेटा कॉपी आणि पेस्ट करावा लागेल. 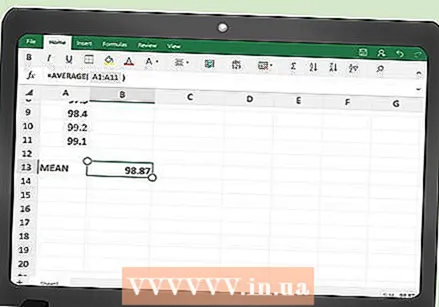 डेटा पॉइंट्सची सरासरी निश्चित करा. एक्सेलमध्ये एक फंक्शन असते जे आपल्यासाठी सरासरीची गणना करते. आपल्या डेटा टेबलच्या खाली असलेल्या रिकाम्या सेलमध्ये (आपण कोणता सेल निवडाल याचा फरक पडत नाही), खाली प्रविष्ट करा:
डेटा पॉइंट्सची सरासरी निश्चित करा. एक्सेलमध्ये एक फंक्शन असते जे आपल्यासाठी सरासरीची गणना करते. आपल्या डेटा टेबलच्या खाली असलेल्या रिकाम्या सेलमध्ये (आपण कोणता सेल निवडाल याचा फरक पडत नाही), खाली प्रविष्ट करा: - = सरासरी (A2: ___)
- रिक्त स्थान प्रविष्ट करू नका. आपल्या शेवटच्या डेटा पॉइंटच्या सेल नावाने ती जागा भरा. उदाहरणार्थ, आपल्याकडे 100 डेटा पॉइंट्स असल्यास, आपण हे कार्य वापरालः
- = सरासरी (A2: A101)
- या फंक्शनमध्ये सेल ए 2 मधील ए 101 मधील डेटा समाविष्ट आहे कारण शीर्ष पंक्तीमध्ये स्तंभ शीर्षलेख आहेत.
- जेव्हा आपण एंटर दाबा किंवा आपण टेबलमधील दुसर्या सेलवर क्लिक करता तेव्हा नवीन प्रोग्राम केलेला सेल स्वयंचलितपणे आपल्या डेटा मूल्यांच्या सरासरीने भरला जातो.
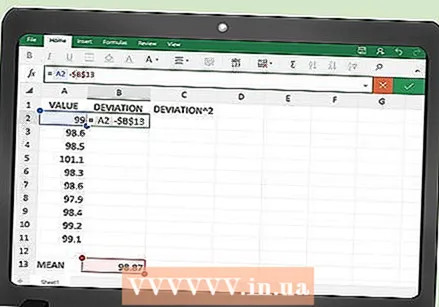 त्रुटी मापनासाठी कार्य प्रविष्ट करा. "विचलन" स्तंभातील पहिल्या रिकाम्या सेलमध्ये, प्रत्येक डेटा बिंदू आणि मध्यमधील फरक मोजण्यासाठी फंक्शन प्रविष्ट करा. हे करण्यासाठी, मध्यभागी जेथे स्थित आहे त्याचे नाव वापरा. समजा आपण आत्तासाठी सेल A104 वापरला आहे.
त्रुटी मापनासाठी कार्य प्रविष्ट करा. "विचलन" स्तंभातील पहिल्या रिकाम्या सेलमध्ये, प्रत्येक डेटा बिंदू आणि मध्यमधील फरक मोजण्यासाठी फंक्शन प्रविष्ट करा. हे करण्यासाठी, मध्यभागी जेथे स्थित आहे त्याचे नाव वापरा. समजा आपण आत्तासाठी सेल A104 वापरला आहे. - आपण सेल बी 2 मध्ये प्रविष्ट केलेले त्रुटी गणना कार्यः
- = ए 2- $ ए $ 104. आपण कोणत्याही गणनासाठी बॉक्स A104 लॉक केल्याचे सुनिश्चित करण्यासाठी डॉलर चिन्हे आवश्यक आहेत.
- आपण सेल बी 2 मध्ये प्रविष्ट केलेले त्रुटी गणना कार्यः
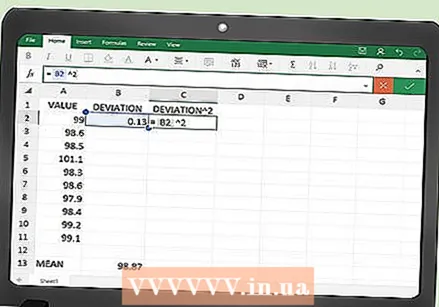 चौरसातील त्रुटींसाठी कार्य प्रविष्ट करा. तिसर्या स्तंभात आपण एक्सेलला इच्छित स्क्वेअर मोजण्यासाठी सूचना देऊ शकता.
चौरसातील त्रुटींसाठी कार्य प्रविष्ट करा. तिसर्या स्तंभात आपण एक्सेलला इच्छित स्क्वेअर मोजण्यासाठी सूचना देऊ शकता. - सेल सी 2 मध्ये, खालील कार्य प्रविष्ट करा:
- = बी 2 ^ 2
- सेल सी 2 मध्ये, खालील कार्य प्रविष्ट करा:
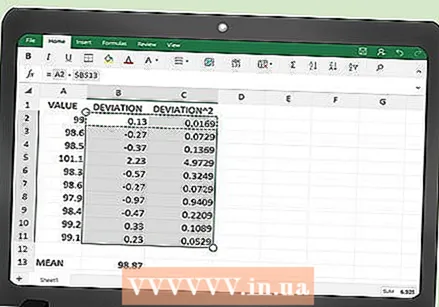 संपूर्ण सारणी भरण्यासाठी कार्ये कॉपी करा. प्रत्येक स्तंभातील शीर्ष सेल अनुक्रमे बी 2 आणि सी 2 मध्ये कार्ये प्रविष्ट केल्यानंतर, आपल्याला संपूर्ण सारणी भरणे आवश्यक आहे. आपण टेबलच्या कोणत्याही ओळीत कार्य पुन्हा टाइप करू शकता परंतु यास बराच वेळ लागेल. आपला माउस वापरुन, सेल बी 2 आणि सी 2 एकत्रित करा आणि माऊस बटण सोडल्याशिवाय प्रत्येक स्तंभातील तळाशी असलेल्या सेलवर ड्रॅग करा.
संपूर्ण सारणी भरण्यासाठी कार्ये कॉपी करा. प्रत्येक स्तंभातील शीर्ष सेल अनुक्रमे बी 2 आणि सी 2 मध्ये कार्ये प्रविष्ट केल्यानंतर, आपल्याला संपूर्ण सारणी भरणे आवश्यक आहे. आपण टेबलच्या कोणत्याही ओळीत कार्य पुन्हा टाइप करू शकता परंतु यास बराच वेळ लागेल. आपला माउस वापरुन, सेल बी 2 आणि सी 2 एकत्रित करा आणि माऊस बटण सोडल्याशिवाय प्रत्येक स्तंभातील तळाशी असलेल्या सेलवर ड्रॅग करा. - आपल्या टेबलमध्ये आपल्याकडे 100 डेटा पॉइंट्स आहेत असे गृहीत धरून, आपला माउस सेल B101 आणि C101 वर ड्रॅग करा.
- आपण माऊस बटण सोडता तेव्हा, सारण्यांच्या सर्व सेलमध्ये सूत्रे कॉपी केल्या जातात. सारणी स्वयंचलितपणे गणना केलेल्या मूल्यांनी भरली पाहिजे.
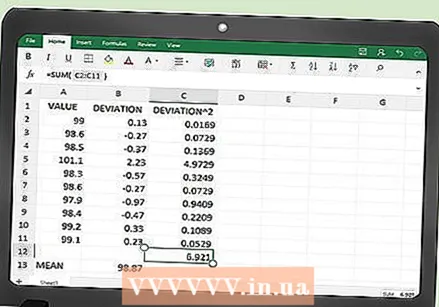 एसएसई शोधा. आपल्या टेबलच्या स्तंभ सीमध्ये सर्व चौरस त्रुटी मूल्ये आहेत. शेवटची पायरी म्हणजे एक्सेलला या मूल्यांच्या बेरीजची गणना करू देणे.
एसएसई शोधा. आपल्या टेबलच्या स्तंभ सीमध्ये सर्व चौरस त्रुटी मूल्ये आहेत. शेवटची पायरी म्हणजे एक्सेलला या मूल्यांच्या बेरीजची गणना करू देणे. - टेबलच्या खाली असलेल्या सेलमध्ये, कदाचित या उदाहरणात C102, खालील कार्य प्रविष्ट करा:
- = बेरीज (सी 2: सी 101)
- आपण एंटर क्लिक केल्यास किंवा टेबलच्या दुसर्या सेलमध्ये क्लिक केल्यास आपल्या डेटाचे एसएसई मूल्य मिळेल.
- टेबलच्या खाली असलेल्या सेलमध्ये, कदाचित या उदाहरणात C102, खालील कार्य प्रविष्ट करा:
- मध्यम स्तंभातील प्रत्येक मूल्यासाठी, चौरस काढण्यासाठी कॅल्क्युलेटर वापरा. तिसर्या स्तंभात खालीलप्रमाणे परिणाम नोंदवाः
- दिलेल्या डेटा सेटसाठी, प्रत्येक मोजल्या गेलेल्या मूल्यापासून 98.87 पर्यंतचे वजा करा आणि परिणामासह दुसर्या स्तंभ भरा. या दहा गणना खालीलप्रमाणे आहेत:
- डेटा सेटचा अर्थ म्हणजे सेटमधील मूल्यांच्या संख्येद्वारे विभाजित केलेल्या मूल्यांची बेरीज. हे व्हेरिएबलसह प्रतिकात्मकपणे दर्शविले जाऊ शकते
पद्धत 3 पैकी एसएसई इतर आकडेवारीशी संबंधित
 एसएसईकडून विचलनाची गणना करा. डेटासेटसाठी एसएसई शोधणे हा सहसा इतर, अधिक उपयुक्त, मूल्ये शोधण्यासाठी बिल्डिंग ब्लॉक असतो. यातील प्रथम भिन्नता आहे. भिन्नता म्हणजे मोजले जाणारे डेटा मधून किती फरक करते. हे खरंतर क्षुद्र पासून चौरस भिन्नतेचे क्षुद्र आहे.
एसएसईकडून विचलनाची गणना करा. डेटासेटसाठी एसएसई शोधणे हा सहसा इतर, अधिक उपयुक्त, मूल्ये शोधण्यासाठी बिल्डिंग ब्लॉक असतो. यातील प्रथम भिन्नता आहे. भिन्नता म्हणजे मोजले जाणारे डेटा मधून किती फरक करते. हे खरंतर क्षुद्र पासून चौरस भिन्नतेचे क्षुद्र आहे. - एसएसई ही चौरसातील त्रुटींची बेरीज असल्यामुळे, मूल्यांच्या संख्येनुसार भागाकार करुन आपण त्याचा अर्थ (तो भिन्नता) शोधू शकता. तथापि, जर आपण संपूर्ण लोकसंख्येऐवजी नमुना मालिकेच्या भिन्नतेची गणना केली तर आपण फरक एन (एन) ऐवजी (एन -1) ने विभाजित करा. तरः
- भिन्नता = एसएसई / एन, जर आपण संपूर्ण लोकसंख्येच्या भिन्नतेची गणना केली तर.
- भिन्नता = एसएसई / (एन -1), जेव्हा डेटाच्या नमुन्याच्या भिन्नतेची गणना करते.
- रुग्णांच्या तपमानाच्या नमुन्याच्या समस्येसाठी आपण असे गृहीत धरू शकतो की 10 रुग्ण फक्त एक नमुना आहेत. म्हणून, भिन्नता खालीलप्रमाणे खालीलप्रमाणे मोजली जाते:
 एसएसईच्या प्रमाणित विचलनाची गणना करा. मानक विचलन हे सामान्यतः वापरले जाणारे मूल्य असते जे डेटा सेटची मूल्ये मधून किती दूर वळते हे सूचित करते. प्रमाण विचलन म्हणजे भिन्नतेचा चौरस मूळ. लक्षात ठेवा भिन्नता चौरस त्रुटी मोजमापांचे मध्य आहे.
एसएसईच्या प्रमाणित विचलनाची गणना करा. मानक विचलन हे सामान्यतः वापरले जाणारे मूल्य असते जे डेटा सेटची मूल्ये मधून किती दूर वळते हे सूचित करते. प्रमाण विचलन म्हणजे भिन्नतेचा चौरस मूळ. लक्षात ठेवा भिन्नता चौरस त्रुटी मोजमापांचे मध्य आहे. - म्हणूनच, एसएसईची गणना केल्यानंतर, आपल्याला यासारखे मानक विचलन आढळेल:
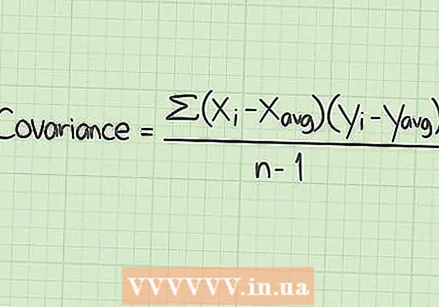 सहकार निर्धारित करण्यासाठी एसएसई वापरा. या लेखाने डेटासेटवर लक्ष केंद्रित केले आहे जे एका वेळी फक्त एकच मूल्य मोजतात. तथापि, बर्याच अभ्यासांमध्ये आपण दोन स्वतंत्र मूल्यांची तुलना करू शकता. उदाहरणार्थ, आपल्याला हे जाणून घ्यायचे आहे की ती दोन मूल्ये केवळ डेटा सेटच्या मध्यभागीच नव्हे तर एकमेकांशी कशी संबंधित आहेत. हे मूल्य सहकारिता आहे.
सहकार निर्धारित करण्यासाठी एसएसई वापरा. या लेखाने डेटासेटवर लक्ष केंद्रित केले आहे जे एका वेळी फक्त एकच मूल्य मोजतात. तथापि, बर्याच अभ्यासांमध्ये आपण दोन स्वतंत्र मूल्यांची तुलना करू शकता. उदाहरणार्थ, आपल्याला हे जाणून घ्यायचे आहे की ती दोन मूल्ये केवळ डेटा सेटच्या मध्यभागीच नव्हे तर एकमेकांशी कशी संबंधित आहेत. हे मूल्य सहकारिता आहे. - कोवेरियन्सची गणना येथे वर्णन करण्यासाठी बरेच तपशीलवार आहे, हे लक्षात घेण्याशिवाय आपण प्रत्येक डेटा प्रकारासाठी एसएसई वापरु आणि नंतर त्याची तुलना करा. सहकार्याविषयी आणि त्यातील गणितांच्या विस्तृत तपशीलासाठी, आपणास विकीहो वर या विषयावरील लेख सापडतील.
- कोवेरियन्सच्या वापराचे उदाहरण म्हणून आपण वैद्यकीय अभ्यासाच्या रूग्णांच्या वयाची ताप ताप कमी करण्याच्या औषधाच्या प्रभावीतेशी तुलना करू शकता. तर आपल्याकडे वयोगटाचा एक डेटा सेट आणि तापमानाचा दुसरा डेटा सेट आहे. त्यानंतर आपल्याला प्रत्येक डेटा सेटसाठी एसएसई सापडेल आणि तेथून भिन्नता, मानक विचलन आणि सहकार्य असेल.
- म्हणूनच, एसएसईची गणना केल्यानंतर, आपल्याला यासारखे मानक विचलन आढळेल:
- एसएसई ही चौरसातील त्रुटींची बेरीज असल्यामुळे, मूल्यांच्या संख्येनुसार भागाकार करुन आपण त्याचा अर्थ (तो भिन्नता) शोधू शकता. तथापि, जर आपण संपूर्ण लोकसंख्येऐवजी नमुना मालिकेच्या भिन्नतेची गणना केली तर आपण फरक एन (एन) ऐवजी (एन -1) ने विभाजित करा. तरः



